Modelización
de la captura y fases de desarrollo de la pesquería de la jaiba azul (Callinectes sapidus) en
la Laguna Madre, Tamaulipas, México
Modelling the catch and development
phases of the blue crab fishery (Callinectes sapidus) in the Laguna Madre, Tamaulipas, Mexico
Jorge Homero Rodríguez-Castro1*,
Alfonso Correa-Sandoval1, José Alberto Ramírez-de-León2,Jorge
Alejandro Adame-Garza3
*Autor
para correspondencia:rodriguezjh@hotmail.com/Fecha de recepción: 20 de octubre
de 2015/Fecha de aceptación: 25 de noviembre de 2016
1Instituto Tecnológico de Ciudad Victoria, Laboratorio
de Zoología, bulevard Emilio Portes Gil núm. 1301 Poniente, Apartado Postal
175, Ciudad Victoria, Tamaulipas, México, C. P. 87010. 2Universidad
Autónoma de Tamaulipas, Unidad Académica de Trabajo Social y Ciencias para el
Desarrollo Humano. Centro Universitario Ciudad Victoria, Tamaulipas, México,
C.P. 87149. 3Universidad Autónoma de Tamaulipas, Facultad de
Medicina Veterinaria y Zootecnia, carretera Ciudad Victoria a carretera Ciudad
Mante km 5, Ciudad Victoria, Tamaulipas, México.
RESUMEN
La captura promedio anual de la
pesquería de la jaiba azul (Callinectes
sapidus) (JA) en Tamaulipas,
México se estima en 2 733 T, de la cual, el 82 % se pesca en la Laguna
Madre, sitio que se considera aprovechado al máximo de su
capacidad. El objetivo de la presente investigación fue modelar
la captura anual de la JA en la Laguna Madre, Tamaulipas,
mediante el ajuste de funciones matemáticas de tipo
lineal y no lineal (o curvilínea), a la serie de tiempo de 1998 a
2012, además de identificar las fases de desarrollo de
la pesquería, de acuerdo a varios modelos
generalizados. Se utilizó el enfoque de la teoría de la
información y el procedimiento de la inferencia multimodelo (IMM). Se ajustaron 11 modelos de regresión lineal
y no lineal. Para la selección de modelos se
utilizaron los criterios de información Akaike
corregido (CIAc) y bayesiano (CIB). Para el
IMM se consideró el nivel ∆i < 2 de plausibilidad de CIAc y CIB. Los modelos elegidos
para el IMM fueron compuesto, crecimiento, exponencial,
logístico, potencial y el sigmoideo, considerándose
como más adecuados los primeros cuatro modelos citados. Los modelos promedio
del IMM presentaron valores de β0 y β1 de 0.939 y 0.377 respectivamente,
según CIAc; y de 0.952 y 0.344 respectivamente, de
acuerdo al CIB. Solo los modelos compuesto y logístico mostraron significancia
estadística en sus dos parámetros de regresión (β0 y β1). El índice de sustentabilidad
pesquera reveló seis periodos de la captura y una disminución en magnitud de
los cambios de la captura. La serie de datos analizada incluye dos ciclos de
vida de acuerdo a los modelos de Csirke y Caddy. Los resultados mostraron que al final del periodo estudiado
la pesquería se encontraba en colapso y
decadencia.
PALABRAS
CLAVE: criterio de información de Akaike,
criterio de información Bayesiano, inferencia-multimodelo,
captura pesquera, Callinectes
sapidus.
ABSTRACT
The average annual catch of the blue crab (Callinectes
sapidus) (BC) fishery in Tamaulipas, Mexico is estimated at 2 733 T, of which the 82 % is caught in the
Laguna Madre, which is considered to be exploited to
the maximum of its capacity. The objective
of the present investigation was to model the annual catch of the BC in the Laguna Madre, Tamaulipas, by adjusting mathematical
functions of the linear and
nonlinear (or curvilinear) type, to the time series from
1998 to 2012. In addition, the phases of development of the fishery, according to several generalized models, were identified.
We used the information theory approach and multimodel inference
procedure (MMI). Eleven linear and nonlinear regression models were fitted. For the
selection of models, the corrected Akaike corrected (AICc) and Bayesian (BIC) information criteria
were used. For the MMI, the level ∆i < 2 of plausibility
of AICc and BIC was considered. The
models chosen for the
MMI were compound,
growth, exponential, logistic, potential and the sigmoid, with the
first four models being considered
the most suitable of all those cited. The
average models of the MMI presented values of β0 and β1: 0.939 and 0.377 respectively, according to CIAc; and 0.952 and 0.344 respectively,
according to the CIB. Only the
composite and logistic models showed statistical significance in their two regression pa-rameters (β0 and β1 ). The
fishery sustainability index revealed six catch periods and a decrease in magnitude of catch changes. The data series analyzed includes two life cycles
according to the Csirke and Caddy models. The results showed that at the end
of the studied period
the fishery was in collapse and decay.
Keywords: Akaike information criterion, Bayesian information criterion, multimodel-inference, fishing catch, Callinectes
sapidus.
INTRODUCCIÓN
En Tamaulipas, la
producción pesquera anual promedio es de más de 52 000 T, con un valor superior
a los 930 millones de pesos aportando el 8.86 % del Producto InternoBruto, dentro del sector agropecuario (Ro-dríguez-Castro y col., 2010). En orden decreciente, las
especies que más contribuyen a la producción pesquera de Tamaulipas son: camarón, Farfantepenaeus aztecus, Ives, 1891 (13 404 T); lisa, Mugil cephalus,
Linnaeus, 1758 (3 990 T); mojarra-tilapia, Oreochromis aureus, Steindachner, 1864 (3 235 T); jaiba azul, Callinectes sapidus, Rathbun, 1896 (2
733 T); ostión, Crassostrea
virginica, Gmelin, 1791 (2 303 T); carpa, Cyprinus carpio, Linnaeus, 1758 (2 261 T) y el grupo denominado tiburón cazón que abarca principalmente a las especies: Rhizoprionodon terraenovae,
Carcharhinus acronotus, Sphyrna lewini, Carcharhinus leucas, Carcharhinus falciformis y Carcharhinus porosus (2 033 T).
Actualmente, la pesquería de la jaiba
azul (JA) de la Laguna Madre, Tamaulipas (LMT), al igual que en el resto del
Golfo de México, se encuentra aprovechada al máximo sustentable (Arreguín-Sánchez y Arcos-Buitrón, 2011; SAGARPA, 2012). En
dicha actividad económica participan más de 3 500 pescadores, y dependen de
ellos más de 15 000 personas ubicadas en los municipios de Matamoros, San
Fernando y Soto La Marina. Esta situación de sobreexplotación reviste crucial
importancia en la LMT, en donde se realiza el 82 % de la captura estatal de
esta pesquería (SAGARPA, 2012).
Arreguín-Sánchez
y Arcos-Huitrón (2011), indicaron que: “en muchos países, un problema común es la
insuficiencia de información clave y continua para la aplicación de modelos que
permitan realizar un diagnóstico confiable del estado de la pesca, y
representar escenarios de manejo con niveles de in-certidumbre y riesgo
calculables. Por lo general, el único dato que parece ser relativamente
consistente son las capturas registradas. Aún con las deficiencias que pudieran
señalarse para los registros de captura de las flotas ribereñas, la tendencia de las capturas, especialmente cuando
se trata de recursos plenamente explotados, suele ser un indicador relativo de
la abundancia del recurso; y la tendencia
puede ofrecer información sobre el estado de la pesca; ya que en muchos
casos, es la única información disponible”. Por ello, en la evaluación de los recursos pesqueros, partiendo de la
información de series de tiempo de captura, como única fuente de
información, es importante
analizar su tendencia.
En el análisis de la
tendencia de las series de
tiempo se incluye, en diferentes métodos, la utilización de funciones
matemáticas para arribar a proyecciones confiables. En tal situación se ubican
los modelos de regresión lineal y no
lineal (o curvilínea). Bajo el marco de la selección de modelos, hay una gama de
modelos que se ajustan a un grupo de datos en particular, tal es caso de las
series temporales, por lo que es necesario establecer un criterio de decisión
para elegir el mejor modelo, como es el de información (Burnham y Anderson, 2004). La inferencia multimodelo (IMM) postula que cuando los datos soportan
evidencia para más de un modelo, en
lugar de estimar los parámetros a partir de sólo “el mejor modelo”, es posible
estimarlos a partir de varios modelos, e incluso todos los modelos considerados.
Obtener el valor promedio de la variable predicha, a partir de varios modelos, es una ventaja para
alcanzar una inferencia robusta, que no
esté condicionada a un sólo
modelo y que integre la aportación
ponderada de cada modelo ajustado (Burnham y
Anderson, 2002).
Con base en las
series de tiempo de la captura pesquera, se han desarrollado modelos generales
de clasificación de las fases de desarrollo de una pesquería (Caddy, 1984; Csirke, 1984), con poca variación en las
descripciones de las fases de crecimiento, y
que definen la vida por etapas de una pesquería. La captura (C) es una cantidad
considerada como índice, que es proporcional a parámetros importantes de la
pesquería, como la mortalidad por pesca y la densidad de la proporción explotada
(Gulland, 1971).
En el plano de la evaluación y manejo de
las pesquerías, en primera instancia,
se tiene que revisar la pesquería a través de
la tendencia de la C, ya que determinará la fase de desarrollo en que se
encuentra, y según la fase de
desarrollo actual, establece la definición de técnicas y objetivos de la
ordenación pesquera que se deberán de
aplicar. Csirke (1984), señala que: “por lo general,
todo cambio en gran escala en un recurso explotado determinará una reacción equivalente en la pesquería. Si
las poblaciones de peces aumentan, lo harán también las tasas de captura, la
captura total y el esfuerzo de pesca. En cambio, si la población disminuye, las
capturas también lo harán, pero el esfuerzo de pesca se reducirá más lentamente
y es posible incluso que se aumente, en el intento de mantener altos niveles de
captura, con lo cual la mortalidad por pesca real aumentará. Esta forma
de comportamiento hace que las pesquerías que son afectadas por importantes fluctuaciones, debidas al ambiente, tengan
mayores posibilidades de llegar a una situación de sobreexplotación”.
La presente investigación tuvo como
objetivo modelar la captura anual de la Jaiba azul en la Laguna Madre,
Tamaulipas, mediante el ajuste de funciones matemáticas de tipo lineal y no
lineal (o curvilínea) a la serie de tiempo, de 1998 a 2012, e identificar las
fases de desarrollo de la pesquería, de acuerdo a los modelos analizados.
MATERIALES Y MÉTODOS
Recopilación de información
La información que se utilizó para este
estudio fue obtenida de la Subsecretaría de Pesca y Acuacultura de la
Secretaría de Desarrollo Rural del Gobierno del Estado de Tamaulipas. El origen
de esta información son los avisos de arribo para embarcaciones menores de las
oficinas de pesca de los municipios de Matamoros, San Fernando y Soto La
Marina, dependientes de la Subdelegación de
Pesca de la Secretaría de Agricultura, Ganadería,
Desarrollo Rural, Pesca y Alimentación (SAGARPA), en Tamaulipas. Los avisos de arribo son formatos oficiales
generados por la SAGARPA, a través de la Comisión Nacional de Pesca y
Acuacultura, para que todos los permisionarios reporten sus capturas de forma mensual. Las
especificaciones de dichos formatos incluyen, entre otras, el nombre de la
especie, el volumen y el valor de la captura
en kilogramos por
mes, principalmente.
Ajuste de modelos
para el análisis de captura (C)
En una hoja de cálculo del software Numbers versión 3.5.3 (2015), se construyó la base de
datos, las gráficas correspondientes y se estimaron los estadísticos básicos
(totales y promedios). Se realizaron ajustes de modelos lineales y no lineales
(estimación curvilínea) a la serie de tiempo de la C de la JA en la LMT durante
el periodo 1998 a 2012, utilizando el software Statistical
Package for the Social Sciences (SPSS, Version 18, 2009). Los modelos aplicados se indican en la
Tabla 1. De cada modelo se obtuvo el
coeficiente de determinación (R2), la prueba F de Fisher, la
probabilidad de significancia; las estimaciones de los interceptos
(β0)
y coeficientes de regresión (β1, β2,
β3), y
las probabilidades asociadas a la prueba t
de estos parámetros en cada modelo
de regresión.

Selección de modelos
La selección de los modelos se basó en
la teoría de la información, específicamente en el Criterio de Información Akaike (1973) (CIA) y Criterio de Información Bayesiano
(CIB), propuesto por Schwarz (1978). De cada modelo se obtuvieron los valores CIAc
(CIAc = CIA corregido, más adelante se indican
las razones de esta corrección) y CIB, así como las diferencias (∆i)
y el peso (wi) para CIAc y
CIB respectivamente. Con estos resultados se procedió a encontrar los valores
más bajos CIAc y CIB, y los más altos de los wi
CIAc y wi CIB, para identificar el mejor o
mejores modelos, del total de los modelos candidatos.
Para complementar estos criterios de selección, también se utilizó la
significancia estadística del β0, β1,
β2, β3,
de cada uno de los modelos candidatos, con base en la probabilidad asociada a
la prueba t.
Criterio de Información Akaike (CIA)
Este criterio se basa en la distancia Kullback-Leibler, que mide la aproximación del modelo
calculado con los datos reales, seleccionando así el mejor modelo candidato (Katsanevakis, 2006; Katsanevakis
y Maravelias, 2008). El enfoque CIAc
permite jerarquizar los modelos, al ordenarlos de forma ascendente, en función
de los valores CIAc. El modelo con el menor valor CIAc será el mejor (Cailliet y
col., 2006; Romine y col., 2006; Griffiths
y col., 2010). Guzmán-Castellanos y col. (2014) establecieron que: “la premisa
más importante del método del CIAc es penalizar la
cantidad de parámetros de cada uno de los modelos, basándose en el principio de
parsimonia; es decir, existe un criterio basado en la bondad de ajuste del
modelo a los datos, definido a través de la función objetivo de máxima
verosimilitud o SSQ (suma de cuadrados), y al mismo tiempo existe una
penalización asociada a la cantidad total de parámetros del modelo. En
consecuencia, se esperaría un mejor ajuste del modelo a los datos, en la medida
que aumenta el número de parámetros de los modelos. El CIAc
equilibra adecuadamente estos dos componentes, y su resultado finales un
criterio cuantitativo para la selección
de modelos”.
Formulación CIA
La expresión
original del CIA es la siguiente:
![]()
Donde −lnL es
el logaritmo natural negativo de verosimilitud estimado por una función logarítmica, y θ es el número de parámetros estimados en cada modelo candidato de
crecimiento.
Sin embargo, en este estudio se utilizó el enfoque de los mínimos
cuadrados, y el parámetro del logaritmo natural
negativo de verosimilitud fue sustituido por la varianza residual de acuerdo al criterio de Burnham
y Anderson (2002), quienes proponen la versión siguiente:
![]()
Donde n = tamaño muestral (número de
datos), 2 = varianza residual (cociente
de la suma de cuadrados residuales y el número de datos), ô2 y K = número
de parámetros del
modelo.
Para esta versión se asumió una distribución normal del error, una media
cero y una varianza constante.
CIA corregido (CIAc)
De acuerdo al
criterio de Burnham y Anderson (2002), si el tamaño
de la muestra es pequeña, es decir, si n/K < 40, que es el presente caso,
entonces se debe usar una forma de estimación de CIA que pueda corre-gir el sesgo,
y la expresión se escribe como:
![]()
Donde CIAc = CIA corregido, CIA = valor de CIA, K = número de parámetros
y n = número de
datos.
Delta (∆i) CIAc
Se siguió el método descrito por Guzmán-Castellanos
y col. (2014), quienes establecen que: “para conocer el soporte estadístico que
tienen los modelos candidatos, que no fueron considerados como el modelo más
adecuado, se estiman las diferencias de Akaike
definidas como ∆i; las cuales de acuerdo con Burnham y Anderson (2002), si ∆i
> 10 denota modelos candidatos sin apoyo estadístico que
no deben ser tomados en cuenta. Por el
contrario, si ∆i < 2 entonces tienen
una alta evidencia como funciones alternativas;
mientras que modelos en los que 4 < ∆i
< 7 pueden ser tomados en cuenta, aunque con menor soporte estadístico que
los anteriores. De tal forma que, ∆i
es un indicador del desempeño de cada modelo
candidato. La formulación para estimar ∆i
se representa como: ∆i = CIAci
− CIAcmin;
donde: CIAcmin
es el modelo candidato con el valor más bajo de CIA que representa el modelo
candidato más adecuado, y CIAci representa el valor
de CIA estimado para los otros
modelos candidatos (i = 1…n)”.
Pesos CIA (wi)
Adicionalmente, para
cuantificar la evidencia a favor que tiene cada modelo candidato, también se
estiman los factores ponderados de Akaike (wi) “pesos Akaike”; cuya expresión
Akaike:
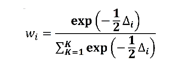
donde ∆i = diferencia Akaike y K = número de
parámetros.
K (Cantidad de parámetros)
La varianza residual ô2
se incluyó como un parámetro más de cada modelo, dado que se utilizó la función
de mínimos cuadrados, recomendada por Burnham y
Anderson (2002).
Criterio de Información Bayesiano (CIB)
También se aplicó el
CIB para la selección del modelo de mejor ajuste, bajo la fórmula
siguiente:
CIB = -2 log(L) + K * log(n)
Donde L = estimador de
máxima verosimilitud, K = número de parámetros (incluyendo la varianza residual
como un parámetro más del modelo) y n =
número de datos.
De igual forma, el estimador de máxima
verosimilitud fue sustituida por la varianza residual. Una vez estimados los
valores CIB, se procedió a estimar el valor de la diferencia ∆i
y el valor de wi
para cada uno de los modelos, de acuerdo al procedimiento indicado para los
correspondientes del CIA, según lo proponen Wagenmakers y Farrel (2004). También se consideró a ô2
como un parámetro del modelo en aplicación. Los pesos CIB pueden ser
interpretados como probabilidades a
posteriori del modelo, dado los datos, el conjunto
de modelos y la probabilidad a posteriori
(1/k) de cada modelo, siendo k el
número de modelos
candidatos.
Criterio de IMM
Se utilizó el criterio IMM, dado que
varios modelos presentaron ajustes adecuados de predictibilidad. Este criterio consiste en rehacer la estimación
completa de los valores de CIAc y/o CIB y de interceptos y
coeficientes de regresión, para el subgrupo de modelos que cumplieron
con el criterio de ∆i < 2 de
plausibilidad. Este carácter de plausibilidad significa que dichos modelos disponen
de soporte estadístico similar, es decir,
que poseen un grado de explicación aceptable, en términos del ajuste de
los modelos de los datos. En consecuencia, los parámetros de interés (β0,
β1
y β2)
de los modelos bajo este criterio (∆i <
2) pueden ser y fueron mejorados. Para lograr esto, se estimó el valor esperado
del parámetro de interés (Ôi),
usando el siguiente estimador:
![]()
De acuerdo a Guzmán-Castellanos y col.
(2014) “este estimador asume que el valor del parámetro Ôi
corresponde a un valor esperado, que cruza sobre todos los
modelos, donde el valor Ōi
debe ser estimado, de manera individual, para
cada modelo candidato que resulta con valores satisfactorios ∆i
< 2. Por consiguiente, este procedimiento explica que el valor de Ôi es mejor que aquel
estimado para Ōi,
sin importar si el valor de Ōi
correspondió al modelo candidato con el mejor valor de CIAcmin o CIB. Esto implica una corrección
al valor de Ōi que mejora el valor del parámetro”. Una vez estimados Ôi
se estimaron sus intervalos de confianza
al 95 %,
con base en
lo siguiente:
![]()
Donde la variable Ōi/g1
corresponde a la varianza estimada de Ōi,
de acuerdo con el ajuste del modelo candidato gi.
De esta manera, además de estimar el mejor valor del parámetro de interés (β0,
β1 y β2),
definido
como Ōi.
También se estimaron sus intervalos
de confianza al 95
%”.
Índice de Sustentabilidad Pesquera
(ISP)
Se identificaron y analizaron los
periodos de expansión y contracción de la captura de la JA en la LMT durante el periodo 1998 a 2012, mediante el ISP
(Ponce y col., 2006), a través de la
ecuación siguiente: ISP = ln (CXiCXmean-1)Donde:
CXi = captura en el año i, CXmean = captura promedio
del total
del periodo.
Fases de la pesquería
Se utilizó la propuesta de Csirke (1984), que refiera a la evolución usual de una
pesquería a lo largo del tiempo, donde se describen las fases siguientes: (1) predesarrollo, (2) crecimiento, (3) explotación plena, (4)
sobreexplotación, en algunos casos (5) colapso y, cuando fue viable (6) recuperación. Asimismo, representa dos tipos de
evolución típica de algunas pesquerías neríticas: un aumento rapidísimo del
esfuerzo de pesca, hasta alcanzar niveles excesivamente altos, y un aumento
moderado, que llega también a niveles altos, pero a ritmo más lento. También se aplicó el modelo generalizado de una pesquería
propuesto por Caddy (1984), en la cual, en el curso
de su desarrollo, debe pasar a través de
cuatro fases: (I) sin desarrollo, (II) de desarrollo, (III) de madurez,
y (IV) de decadencia. En este modelo van implícitos los conceptos de la
capacidad de carga y el esfuerzo pesquero, que corresponde este último a la
tasa de extracción.
La fase sin desarrollo se caracteriza
porque los recursos son explotados de forma limitada, por debajo de su
potencial, con técnicas de pesca poco
eficientes y muchas veces artesanales. Es importante considerar que, de
acuerdo con Grainger y García (1996): “la fase de
desarrollo o de crecimiento se caracteriza por un ritmo rápido de aumento de las capturas, concomitante con un crecimiento
del número de embarcaciones y pescadores
y con el perfeccionamiento y modernización de los sistemas de pesca. Con
las ganancias que se obtienen, al iniciarse esta fase, se estimula el
desarrollo de nuevas inversiones y un incremento aún mayor del esfuerzo de pesca. La fase de madurez se caracteriza porque
todavía se puede apreciar un aumento de las capturas; el aproximarse, en la
mayoría de los casos, a la captura máxima sostenible, determina que, aunque las
capturas totales pueden aumentar, la tasa de incremento de las capturas disminuye rápidamente. Sin embargo, por la propia
inercia del proceso inversionista, resulta difícil reducir el esfuerzo pesquero
de manera inmediata y, por consiguiente, puede pasarse rápidamente a la fase
de decadencia, que conlleva una disminución de las capturas debido a la
sobrepesca, a veces exagerada por cambios ambientales desfavorables. La
duración de las diferentes fases y su nivel de inclinación, dependerán tanto de la tasa del
incremento de las capturas, como de
la capacidad de carga del ecosistema, para cada una de
las especies”.
RESULTADOS
Y DISCUSIÓN
Tendencia de la captura (C)
Además de la regresión lineal, en este
estudio también se utilizó la estimación curvilínea (regresiones no lineales),
bajo el supuesto de que los factores que han ocasionado patrones o tendencias
en el pasado y en el presente, reflejados en
una serie de tiempo, continuarán haciéndolo, más o menos, de la misma forma en el futuro (Bello y Martínez, 2007). En
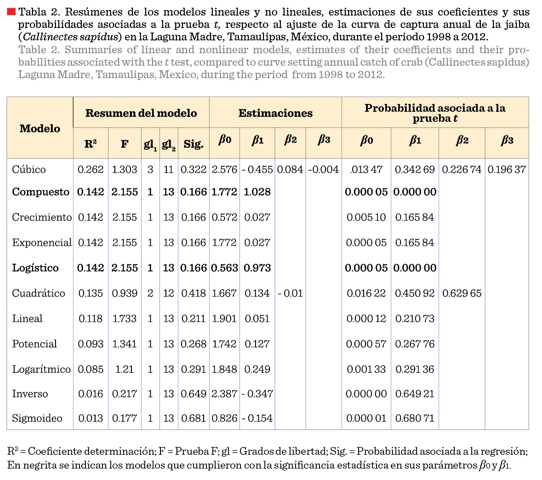
la Tabla 2 se muestran las estimaciones de R2, prueba F, gl1,
gl2 (gl = grados de libertad) y de la
probabilidad de significancia de las regresiones; así como las estimaciones de β0,
β1,
β2,
β3
y de sus respectivas probabilidades
asociadas a la
prueba t, de
los 11 modelos aplicados. El valor más alto de R2 lo obtuvo el
modelo cúbico (0.262), mientras que el
valor más bajo correspondió al sigmoideo
(0.013). Después del modelo cúbico, los
modelos compuesto, crecimiento, exponencial y logístico, ocuparon el
segundo lugar, respecto al valor de R2, con un valor similar de
0.142 cada uno. Estos cuatro modelos mostraron el mismo valor en la prueba F (F
= 2.155), siendo el más alto de todos los modelos. Los 11 modelos ajustados a
los datos de C de la JA, de la LMT, presentaron valores de β0 con
significancia estadística, de acuerdo a la prueba t
(todos diferentes de cero) (P < 0.05), mientras que con respecto al
parámetro β1,
solo los modelos compuesto y logístico
presentaron valores significativamente diferentes de cero (P < 0.05),
según la prueba de t.
Estos dos últimos modelos fueron los únicos en donde ambos parámetros de la
regresión (β0
y β1)
fueron significativos estadísticamente (P
< 0.05). Finalmente, los valores de los parámetros β2, de los modelos cúbico
y cuadrático, y β3
del modelo cúbico, no fueron diferentes de cero (P <
0.05).
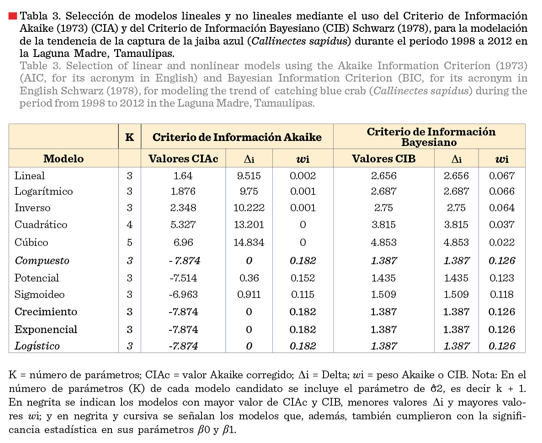
En la Tabla 3 se observan los valores
estimados de CIAc y
CIB, y sus correspondientes valores de ∆i y wi, para cada uno de
los 11 modelos aplicados. Los modelos compuesto, crecimiento exponencial y logístico presentaron los menores valores de ∆i de CIAc y CIB, y los mayores de wi para ambos
criterios, siendo ∆i de CIAc = 0.000, ∆i de CIB = 1.387; wi de CIAc = 18.2 %, y wi de CIB = 12.6 %. Considerando el nivel de ∆i
< 2 de plausibilidad, que indica soporte estadístico similar para los modelos que lo cumplan, los modelos que quedaron incluidos en
este nivel fueron el compuesto,
potencial, sigmoideo, crecimiento, exponencial y logístico, tanto para
el criterio CIAc como el criterio CIB; por lo que
dichos modelos fueron los que se utilizaron para aplicar el criterio de IMM.
Estos seis modelos sumaron el 99.6 % de los wi, de la
totalidad de los 11 modelos utilizados inicialmente. La suma del wi
de los cuatro modelos que presentaron mejor ajuste (compuesto, crecimiento, exponencial y logístico) fue del 73 %. En consecuencia, es recomendable
el nivel ∆i < 2 de plausibilidad para
incrementar el wi y
utilizar los modelos en el
enfoque IMM.
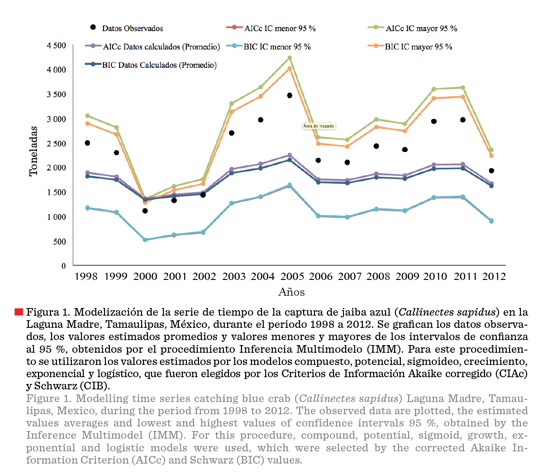
En la Figura 1 se presentan las series
de tiempo de la C de la JA de la LMT, con datos observados y datos calculados.
Estos últimos incluyen los valores promedio, producto de la sumatoria de los
valores ponderados de los parámetros de los modelos compuesto, potencial,
sigmoideo, crecimiento, exponencial y logístico; y valores máximos y mínimos de
los intervalos de confianza al 95 %, obtenidos al utilizar el procedimiento
IMM, basado en la aplicación de los criterios de información CIAc y CIB, como criterios de selección de modelos. En la
gráfica se aprecia que los valores promedio y de datos observados, quedan incluidos en los intervalos de confianza de los valores
estimados, al aplicar ambos criterios de información, CIAc
y CIB; lo que redunda en una robustez de la modelización de la tendencia de
la captura de
la JA en
la LMT.
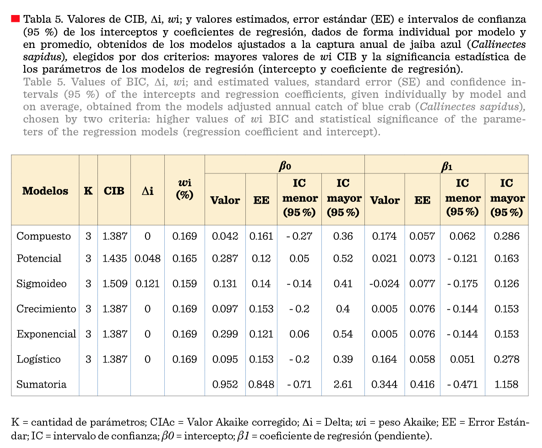
En la Tabla 4 se
muestran los resultados del procedimiento IMM con base en CIAc
y en la Tabla 5 se observan con base en CIB. En este procedimiento se
reajustaron los modelos elegidos bajo el nivel ∆i< 2 de plausibilidad, en ambos criterios (CIAc y CIB). Excepto los modelos potencial y sigmoideo, el
total de los modelos (compuesto, crecimiento exponencial y logístico)
presentaron valores similares de los Criterios de
Información para el caso CIAc, ∆i y wi (- 7.874, 0.000 y 0.183 respectivamente); y
para el criterio CIB, ∆i y wi (1.387,
0.000 y 1.69 respectivamente). Sin embargo,
los seis modelos quedaron incluidos en el rango de ∆i < 2, por lo que se procedió nuevamente a estimar sus
respectivos valores de β0 y β1, calcular sus errores estándar
(EE) y valores mayores y menores de sus intervalos
de confianza al
95 %.
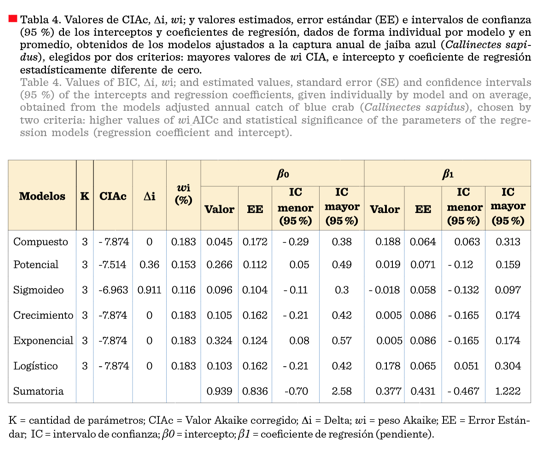
Los valores de β0 (939 T y 952 T), de acuerdo a los criterios CIAc (Tabla 4) y CIB (Tabla 5) respectivamente, representan
el promedio teórico de las capturas anuales de jaiba, asumiéndose
la certeza de que en algún año no
existiera captura. El valor se considera teórico
porque este escenario no es factible, excepto
si se aplicara una veda. El coeficiente β1, con valores de
0.377 y 0.344 (es decir,
37.7 % y 34.4 %), según los criterios CIAc y CIB respectivamente, representan la tasa de
cambio anual; es decir, que cada año la captura
varía en promedio 377 T o 344 T de JA en la LMT. Los intervalos de confianza para β0 fueron - 0.70 a 2.58
y - 0.71 a 2.61, y los correspondientes para β1 fueron
- 0.467 a 1.222 y - 0.471 a 1.158, de acuerdo a los criterios CIAc y CIB respectivamente.
Bajo el marco de la incertidumbre estadística, a menor EE mayor precisión de estimadores obtenidos. En
este caso, no tiene sentido ubicar el menor
EE de los parámetros de la regresión,
dado que se contrapone con los wi: a
menor EE menor wi; y esto ocurre porque el presente análisis es bajo
el enfoque IMM que sopesa a cada modelo y
genera las bases para una sumatoria de valores, más que la individualización de cada
uno.
Es recomendable el uso de criterios de
información, en particular CIAc y CIB, dado que ofrecen las ventajas de que pueden ordenar jerárquicamente a los
modelos según su ajuste a los datos,
y la obtención de sus parámetros promedio. La ordenación jerárquica de los
modelos se da en función de los valores CIAc y/o CIB;
comparando este valor entre los modelos, y aquel que resulta con el valor más
bajo (también reflejado en el menor valor de ∆i
y en el mayor valor del wi) se considera el mejor modelo (Cailliet, y col., 2006; Romine y col., 2006 y Griffiths y
col., 2010). Cabe señalar que la estimación del
o los parámetros promedios deseados se
estiman obteniendo la ponderación Akaike y Schwarz (Burnham y Anderson, 2002). Esto significa que la
contribución de cada parámetro es ponderada antes de obtener el promedio de los
parámetros deseados. En este caso, la estimación de β0 y
β1
y promedios, siguiendo el enfoque IMM, fue de 0.939 según CIAc
y 0.952 de acuerdo a CIB, pero no corresponde a un promedio aritmético de los β0 y
β1
de todos los modelos. En su lugar,
es la sumatoria de cada β0 y
β1
multiplicada por la ponderación (wi %),
y con esto se otorga el peso de cada modelo a la estimación de β0 y
β1
promedio. Es importante indicar que el uso de R2,
ajustada o no, y la suma de cuadrados (SRC), no toma en cuenta la estructura
del modelo que mejor se ajusta a los datos, sino que la decisión de
seleccionarlo se basa en la complejidad del mismo (Aragón-Noriega, 2013). De
hecho, R2 ajustada o no, y la suma de cuadrados, tienden a
seleccionar el modelo más complejo (Zhu y col.,
2009). Por el contrario, el CIAc se rige bajo el
principio de parsimonia y selecciona el
modelo más simple, porque penaliza la adición de más parámetros al
modelo (Burnham y Anderson, 2002), lo mismo ocurre
con el CIB. En este sentido, Burnham y Anderson
(2002), expresan que R2 es una medida de la descripción y de la variación del ajuste del modelo, sin embargo,
no es un criterio útil para seleccionar un modelo que compita por describir los
datos observados. En el presente estudio se mostró esta tendencia: el mejor
modelo, de acuerdo a R2 fue el modelo cúbico (R2 =
0.262), pero fue el que presentó una mayor cantidad de parámetros (5), por el
contrario: los que fueron incluidos en el enfoque IMM fueron los modelos con
solo tres parámetros
(Tabla 2).
Es importante indicar que en este
estudio se utilizó la varianza residual, obtenida por el cociente de la suma de
las diferencias cuadráticas (SSQ), entre el
número de datos, en la aplicación de los criterios de información CIAc y CIB. Al utlizar este
criterio [uso de la varianza residual en sustitución de la técnica de máxima
verosimilitud (MV)] a cada uno de los modelos, además β0 y
β1,
se le sumó otro parámetro, por considerar a la varianza residual (ô2),
como un parámetro más del modelo, según lo recomendado por Katsanevakis
(2006), Katsanevakis y col. (2007) y Katsanevakis y Marvelias (2008).
Se ha observado que el procedimiento de MV tiende a seleccionar el modelo con
el mayor número de parámetros, al incrementar el tamaño de muestra; además,
requiere que los modelos comparados estén anidados, es decir, un modelo
reducido de una versión completa (Gelfand y Dey,
1994, citado por Domínguez-Viveros y col., 2009). Los criterios de CIAc y CIB incurren en el valor de la función de MV,
tomando en cuenta el número de parámetros y la cantidad de información; el mejor modelo es aquel que presenta el menor
valor. En particular, el criterio CIA permite la comparación entre modelos no
anidados; mientras que el criterio CIB no tiende a seleccionar el modelo más parametrizado, cuando el tamaño de
muestra aumenta. El criterio CIB tiende
a seleccionar modelos más simples que los que seleccionaría CIA (Gelfand y Dey
1994; Zucchini, 2000).
Índice de
Sustentabilidad Pesquera
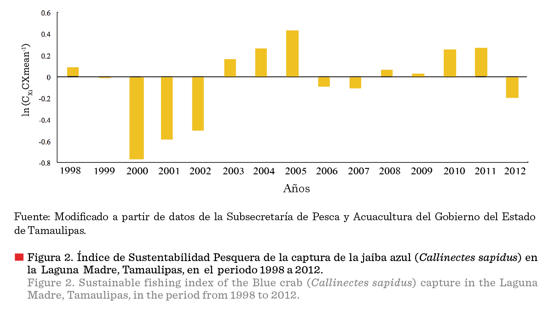
En el periodo de análisis (1998 a 2012)
la producción pesquera de la JA en la LMT, fluctuó entre 1 104 T y 3 462 T, con un promedio
anual de 2 310 T (Figura 2). En la serie de tiempo revisada, y de acuerdo al
ISP, se identificaron seis periodos de 1998 a 1999, 2000 a 2002, 2003 a 2005, 2006 a 2007, 2008 a 2011, y el año 2012;
y los promedios de cada uno de ellos fueron:
2 400 T, 1 285 T, 3 044 T, 2 259 T, 2 954 T y 1 927 T, respectivamente. Las tasas de cambio entre periodos
fueron de la forma siguiente: 1° y 2°
= - 46 %; 2° y 3° = 137 %; 3° y 4° = - 26 %; 4° y 5° = 31 %; y, 5° y 6° = - 35 %. Se observa que el cambio
positivo más grande ocurre entre los periodos 2° y 3°, y el negativo se dio
entre los periodos 1° y 2°, y que los cambios que se registran, tanto positivos
como negativos, revelan una disminución en su
magnitud en la medida que avanza la temporalidad. El ISP es relativamente reciente y permite revisar una panorámica
clara y rápida sobre la evolución
de la pesquería
que se trate.
En términos de evaluación de un recurso
pesquero, el análisis de la tendencia de una serie de tiempo, tradicionalmente
se recurre a la biomasa de la pesquería, entre otros parámetros, cuando los
datos se disponen, y se llegan a expresar puntos de referencia pesqueros en
función de los niveles de la biomasa (Cadima, 2003). Sin embargo, también la captura de algunas pesquerías en el mundo
ha sido objeto de análisis bajo el enfoque
de la tendencia y la identificación de las fases de las pesquerías (Grainger
y García, 1996; Froese y Kesner-Reyes, 2002; 2009; FAO, 2010; Froese y Pauly, 2003; Worm y col., 2006; 2007; Pauly y
col., 2008; Zeller y col., 2009; Kleisner
y Pauly, 2011; Garibaldi, 2012). En particular, estos
autores han analizado los datos globales de captura para obtener información
sobre el estado de las pesquerías mundiales, revelando
por ejemplo, un aumento en los stocks (volumen de biomasa de las
poblaciones pesqueras) colapsados y una disminución de
nuevos stocks.
Fases de la pesquería
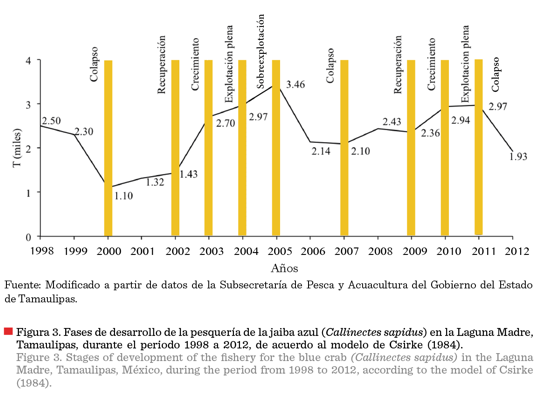
Al aplicar la propuesta de
caracterización de la vida de una pesquería de Csirke
(1984), a la serie de tiempo de la captura
de la JA en la LMT, durante el periodo 1998 a 2012, pero
omitiendo la tendencia de la abundancia,
se identificaron con sus respectivos periodos, las fases siguientes:
fase de colapso: 1998 a 2000; fase de recuperación: 2000 a 2002; fase de
crecimiento: 2002 a 2003; fase de explotación plena: 2003 a 2004; fase de sobreexplotación: 2004 a 2005; fase de
colapso: 2005 a 2007; fase de recuperación: 2007 a 2009; fase de crecimiento:
2009 a 2010; fase de explotación plena: 2010
a 2011 y fase de colapso: 2011
a 2012 (Figura 3).
De igual forma, y de
acuerdo al modelo de las fases de una pesquería, propuesto por Caddy (1984), en la pesquería de la JA en la LMT, durante
el periodo 1998 a 2012, se identifican las fases en los periodos siguientes:
fase IV decadencia: periodo 1998 a 2000; fase I sin desarrollo: periodo 2000 a
2002; fase II en desarrollo: periodo 2002 a 2003; fase III de madurez: periodo
2003 a 2005; fase IV de decadencia: periodo 2005 a 2007; fase I sin desarrollo:
periodo 2007 a 2009; fase II en desarrollo: periodo 2009 a 2011; y fase IV de decadencia: periodo
2011 a 2012
(Figura 4).
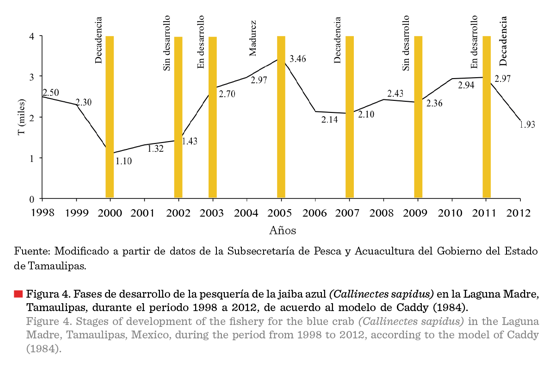
La amplitud de la
serie de datos y la misma tendencia, permiten registrar dos ciclos de vida de la pesquería de acuerdo a estos modelos, que incluyen las
fases de recuperación, crecimiento, explotación plena, sobre-
explotación y
colapso, en el caso del modelo de Csirke
(1984) y las fases de sin desarrollo, en desarrollo, madurez y decadencia,
incluidas en el
modelo de Caddy
(1984).
Un diagnóstico de
una pesquería, basado solamente en la captura total, dispone de
mayor representatividad a mayor longitud de la
serie de datos. Según han señalado Grainger y García
(1996) y la FAO (1999), cuando existe una serie histórica
suficientemente larga y han ocurrido cambios
significativos en la pesquería, el modelo generalizado discutido con
anterioridad permite un diagnóstico del estado actual de la pesquería, a partir
de la observación de la fase de desarrollo alcanzada. Sin embargo, la serie de
datos aquí utilizada, contabiliza más de una década de años, por lo que
representa un claro indicio de la posible evolución de la pesquería en cuestión
en el periodo de estudio, e incluye la totalidad de las fases de
desarrollo que caracterizan
a una pesquería.
Una de las características comunes a
muchas series de tiempo es la
presencia simultánea de una tendencia
de largo plazo y una componente cíclica estacional con un periodo fijo
(Velásquez y Franco, 2012). La serie de tiempo analizada en este estudio
incluyó dos ciclos de “vida” de una
pesquería, de acuerdo a los modelos de Csirke (1984)
y de Caddy (1984), donde el primero incluyó
cinco fases y el segundo cuatro en un
periodo de 14 años. Cabe señalar que
el concepto de ciclo no tiene una
periodicidad fija, y además es un término
inapropiado matemáticamente, pero es
utilizado porque es el que mejor correspondencia tiene con el uso popular de la
palabra “ciclo” (Caddy, 1984).
CONCLUSIONES
Los modelos compuesto, crecimiento,
exponencial y logístico, presentaron el mejor ajuste a los datos analizados, de
acuerdo a los Criterios de Información Akaike y
Bayesiano, los cuales fueron utilizados para
estimar el modelo promedio, según el
procedimiento de la inferencia multimodelo. Bajo el
enfoque de selección de modelos, los
mejores modelos para representar la tendencia de la captura de la jaiba
azul en la Laguna Madre de Tamaulipas fueron
los modelos compuesto y logístico. El índice de sustentabilidad
pes-quera reveló seis periodos de la serie de tiempo de captura de la jaiba
azul de la Laguna Madre Tamaulipas, durante el periodo 1998 a 2012; y una
tendencia a la disminución de la magnitud de los cambios de la captura. Durante
el periodo 1998 a 2012 se identificaron dos ciclos de vida para esta pesquería. Es importante destacar, que los
modelos utilizados señalaron, que en el último año del periodo de estudio
(2012), la pesquería de la jaiba se encontraba en una etapa de colapso y en
decadencia, por lo que se requiere mantener en estudio la evolución de la pesquería para mantener la sustentabilidad de
la actividad económica.
REFERENCIAS
Akaike, H.
(1973). Maximum likelihood identification of Gaussian autoregressive moving average models. Biometrika.
60(2): 255-265.
Aragón-Noriega,
E. A. (2013). Modelación del crecimiento individual del callo de hacha Atrina maura (Bivalvia: Pinnidae) a partir de la inferencia multimodelo. Revista de Biología
Tropical. 61(3):
1167-1174.
Arreguín-Sánchez,
F. y Arcos-Huitrón, E. (2011). La pesca en México:
estado de la explotación y uso de los
ecosistemas. Hidrobiológica. 21(3): 431-462.
Bello,
L. D. y Martínez, S. (2007). Una metodología de series de tiempo para el área
de la salud; caso práctico. Revista
Facultad Nacional de Salud Pública.
25(2): 118-122.
Burnham, K.
P. and Anderson, D. R. (2002). Model Selection and Multimodel Inference: A Practical Information Theoretic Approach. New York: Springer. 488 Pp.
Burnham, K.
P. and Anderson, D. R. (2004). Multimodel inference understanding AIC and
BIC in model selection. Sociological methods
& research.
33(2): 261-304.
Caddy, J. F.
(1984). An alternative to equilibrium theory for management of fisheries. Food and Agricultural Organization (FAO),
in Papers presented
at the Expert Consultation on the regulation of Fishing Effort (fishing mortality). [En línea]. Disponible en: http://www.fao.org/3/a-ac749e/AC749E15.htm.Fecha de
consulta: 25 de
mayo de 2014.
Cadima, E. L.
(2003). Manual de evaluación de recursos pesqueros. FAO Documento Técnico de Pesca. No. 393. Roma: FAO.162 Pp.
Cailliet, G.
M., Smith, W. D., Mollet, H. F., and Goldman, K. J. (2006). Age
and growth studies of chondrichthyan fishes: the need for
consistency in terminology,
verification, validation,
and growth function fitting. Environmental Biology of Fishes. 77: 211-228.
Csirke, J.
(1984). Report of the working Group on
fisheries management, implications and interactions, in
FAO Fisheries
Report, Food and Agriculture Organization of the United Nations.
[En línea]. Disponible en:
http://www.fao.org/docrep/005/x6849e/X6849E06.htm#ch5.
Fecha de consulta: 9 de septiembre de
2015.
Domínguez-Viveros,
J., Rodríguez-Almeida, F. A., Ortega-Gutiérrez, J. A. y Flores-Mariñelarena, A. (2009).
Selección de modelos, parámetros genéticos y tendencias genéticas en las
evaluaciones genéticas nacionales de bovinos Brangus
y Salers. Agrociencia. 43(2): 107-117.
FAO, Food and Agriculture Organization of the United Nations (1999). La ordenación pesquera. FAO
orientaciones Técnicas para
la Pesca Responsable. 4(1):
1-12.
FAO,
Food and Agriculture Organization of the United Nations (2010). The State of World
Fisheries and Aquaculture
2010. A Report
of the Food and Agriculture Organization of the United Nations. Food and Agriculture
Organization of the United Nations, Roma. FAO Fisheries and Aquaculture Department. 197 Pp.
Froese, R. and Kesner-Reyes, K. (2002). Impact
of fishing on the abundance of marine species. Council Meetings Report.
International Council for the Exploration
of the Sea.
Conpenhagen, Denmark. [En línea].
Disponible en:
http://www.ices.dk/sites/pub/CM%20Doccuments/2002/L/L1202.pdf.
Fecha de consulta: 10 de septiembre
de 2015.
Froese, R. and Kesner-Reyes, K. (2009). Out of
new stocks in 2020: a comment on
“Not all fisheries will be collapsed in 2048”. Marine Policy. 33(1): 180–181.
Froese, R. and Pauly, D. (2003). Dynamik der Überfischung. In J. I. Lozan, E. Rachor, K. Reise, J. Sündermann, and H. V. Westernhagen
(Eds.), Warnsignale aus Nordsee and Wattenmeer – Eine aktuelle Umweltbilanz (pp. 288–295). Auswertungen,
Hamburg: Geo, Wissenschaftliche.
Garibaldi,
L. (2012). The FAO global capture production
database: a six-decade effort to catch the trend. Marine Policy. 36(3): 760–768.
Gelfand, A.
E. and Dey, D. K. (1994). Bayesian model choice: asymptotic
and exact calculations. Journal
of the Royal
Statistical
Society. 56(3): 501–514.
Grainger, R.
J. R. and Garcia, S. M. (1996). Chronicles of marine fishery
landings (1950-1994): trend
analysis
and fisheries potential Rome: FAO. 51 Pp.
Griffiths, S.
P., Fry, G. C., Manson, F.
J., and Loü, D. C. (2010). Age
and growth of long tail tuna (Thunnus tonggol) in tropical and temperate
waters of the central Indo-Pacific. ICES Journal
of Marine Science. 67(1): 125-134.
Gulland, J.
A. (1971). Manual de
métodos para la evaluación de las poblaciones de peces. Zaragoza, España: Acribia. 271 Pp.
Guzmán-Castellanos,
A. B., Morales-Bojórquez, E. y Balart, E. F. (2014).
Estimación del crecimiento individual en elasmobranquios: la inferencia con
modelos múltiples. Hidrobiológica. 24(2):
137-150.
Katsanevakis,
S. (2006). Modelling fish growth: Model selection,
multi-model inference and model selection uncertainty. Fisheries Research. 81(2): 229-235.
Katsanevakis,
S. and Maravelias, C. D. (2008). Modelling
fish growth: multi-model inference as a better alternative to a priori using von Bertalanffy
equation.
Fish
and Fisheries. 9(2): 178-187.
Katsanevakis,
S., Thessalou-Legaki, M., Karlou-Riga,
S., Lefkaditou, E. Dimitriou,
E., and Verriopoülos, G. (2007). Information-theory
approach to allometric growth of marine organisms. Marine biology.
151(3): 949-959.
Kleisner, K.
and Pauly, D. (2011). Stock-catch status plots of fisheries for Regional Seas. In The state of biodiversity and fisheries in Regional Seas. Fisheries
Centre Research Report. 19(3):
37-40.
Pauly, D., Alder, J., Booth, S., Cheung, W. W. L., Christensen,
V., Close, A., and Wood, L. (2008). Fisheries in large marine ecosystems: descriptions and diagnoses. The UNEP Large Marine Ecosystem Report: a Perspective on Changing Conditions
in LMEs of the World’s Regional Seas. UNEP Regional
Seas Reports and
Studies.
(182): 23-40.
Ponce,
D. G., Arreguín, F., Beltrán, L. F., Beltrán, M. L. F., Urciaga, J. y
Ortega, A. (2006). Indicadores de
sustentabilidad y pesca: casos en Baja California Sur, México. En L. F. Beltrán-Morales, J. Urciaga-García y A. Ortega-Rubio (Eds.), Desarrollo sustentable: ¿Mito o realidad?. (pp. 183-272). La Paz. B.C.S.,
México: Centro de Investigaciones Biológicas
del Noroeste, S. C.
Rodríguez-Castro,
J. H., Adame-Garza, J. A. y Olmeda-de-la-Fuente, S. E. (2010). La actividad
pesquera en Tamaulipas: Ejemplo Nacional. CienciaUAT.
4(4): 28-35.
Romine, J. G., Grübbs, R. D., and Müsick, J. A. (2006). Age and growth of the sandbar
shark, Carcharhinusplumbeus,
in Hawaiian waters through vertebralanalysis. Environmental Biology of Fishes. 77(3-4): 229-239.
SAGARPA,
Secretaría de Agricultura, Ganadería, Desarrollo Rural, Pesca y Alimentación
(2012). Acuerdo por el que se da a conocer la Actualización de la Carta
Nacional Pesquera, en Diario
Oficial de la Federación. [En línea].
Disponible en:
http://www.inapesca.gob.mx/portal/documentos/publicaciones/CARTA%20NACIONAL%20PESQUERA/24082012%20SAGARPA.pdf. Fecha de consulta: 22 de mayode 2014.
Schwarz, G.
(1978). Estimating the dimension of a model. The
annals
of statistics. 6(2):
461-464.
Velásquez,
J. D. y Franco, C. J. (2012). Pronóstico de series de tiempo con tendencia y
ciclo estacional usando el modelo airline y redes
neuronales artificiales. Ingeniería y
Ciencia. 8(15): 171-189.
Wagenmakers, E.
J. and Farrell, S. (2004). AIC model
selection using Akaike weights. Psychonomic bulletin &
review.
11(1):
192-196.
Worm, B., Barbier, E. B., Beaumont, N., Duffy,
J. E., Folke, C., Halpern,
B. S., …, and Watson, R. (2006). Impacts of biodiversity loss on ocean ecosystem
services.
Science. 314 (5800): 787-790.
Worm, B., Barbier, E. B., Beaumont, N., Duffy,
J. E., Folke, C., Halpern,
B. S., ..., and Watson, R. (2007). Response to comments
on ‘‘Impacts of biodiversity loss on ocean ecosystem
services’’. Science. 316 (5829):
1285d-1285d.
Zeller, D., Cheung, W., Close, C., and Pauly, D. (2009). Trends in global marine fisheriesa critical
view. In Fisheries, trade and development. Royal Swedish Academy of Agriculture
and Forestry, Stockholm. 87–107 Pp.
Zucchini, W.
(2000). An introduction to model selection. Journal of mathematical psychology. 44(1):
41–61.
Zhu, L., Li,
L., and Liang, Z. (2009). Comparison
of six statistical approaches in the selection of appropiate fish growth models.
Chinese Journal
of Oceanology
and Limnology. 27(3): 457-467.